A Guide to Detecting and Managing Cloud Cost Anomalies

- The Key Types of Cloud Cost Anomalies
- Cloud Cost Anomalies vs. Normal Spending Fluctuations
- How to Differentiate Anomalies from Fluctuations
- Best Practices for Cost Monitoring, Managing, and Preventing Anomalies
- Tools and Platforms You Can Use to Detect Anomalies
- Using Machine Learning and AI for Detecting and Managing Cloud Cost Anomalies
- Key Performance Indicators to Keep an Eye on
- Implementing KPIs
- Steps to Resolve Cloud Cost Deviations Once Detected
- Conclusion
In cloud computing, cost anomalies refer to unexpected increases or deviations in expenses that significantly differ from your expected spending patterns. These anomalies are critical to identify – not only because they can quickly lead to budget overruns – but also indicate potential issues in resource management.
Typically, cloud cost deviations occur when actual spending exceeds the planned budget due to misconfigurations, unanticipated spikes in usage, or external circumstances such as provider pricing changes or regional outages. For example, an incorrectly configured auto-scaling policy might allocate too many costly cloud resources during a low-traffic period, triggering a sudden increase in costs. Similarly, promotional activities or unforeseen increases in customer demand can drive up resource consumption.
To identify these anomalies, companies rely on specialized monitoring and analytics tools that compare real-time spending against historical data and predefined thresholds. This data-driven approach makes it possible to detect outliers and isolate the root causes quickly. The early detection of such cloud cost anomalies is crucial for quick responses, for example, scaling down redundant resources, adjusting configurations, or optimizing workloads. By understanding and tracking the factors behind cloud anomalies, you not only safeguard your budgets but also optimize their overall cloud operations. This guide will help you better understand cloud anomalies – to be proactive in managing costs, maintaining financial efficiency, and operational stability.
The Key Types of Cloud Cost Anomalies
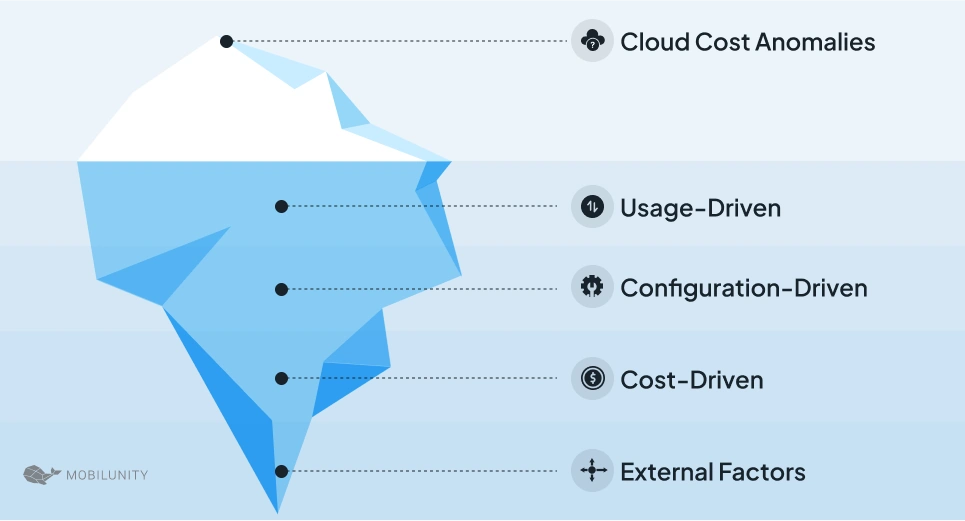
Cloud cost deviations can arise from various sources, each impacting your overall cloud expenses in different ways. Understanding these anomalies is the first step toward effective cost management and prevention of cost overruns. The most common types include usage-driven, configuration-driven, and cost-driven anomalies, along with other variations commonly related to external factors and hidden costs.
Usage-Driven Anomalies
These anomalies appear when actual cloud resource consumption exceeds anticipated levels. For example, if a sudden influx of users during a product launch drives up compute hours or data processing, costs can spike unexpectedly. Monitoring and setting cloud and usage alerts is critical to catching these fluctuations early.
Configuration-Driven Anomalies
Misconfigured resources are a common pitfall in cloud environments. Imagine setting up an auto-scaling group with overly aggressive scaling rules, causing your cloud infrastructure to spin up excessive instances even when demand is low. Another example is accidentally provisioning premium instances or storage options that aren’t needed for your workload. Regular configuration reviews and automated checks can help detect and resolve these issues.
Cost-Driven Anomalies
Sometimes, the deviation isn’t about increased cloud usage or misconfiguration but a change in cost structure. For instance, a cloud provider might revise pricing for certain services, leading to an unforeseen increase in your bill. Alternatively, you might face hidden costs such as data transfer fees or increased charges for third-party integrations. Detailed billing analysis and cost prediction models are essential to manage these surprises.
External Factors
External events can also lead to anomalies. Regional outages may force your system to utilize backup resources in more expensive zones, or sudden market changes might affect currency exchange rates impacting international billing. These external influences require robust contingency planning and adaptive cloud strategies to ensure cost stability.
Cloud Cost Anomalies vs. Normal Spending Fluctuations
Not every surge in your cloud bill signals a problem. Cloud cost fluctuations can stem from many legitimate sources (seasonal demand cycles, marketing campaigns, scheduled maintenance tasks, or tiered discount programs). Understanding these normal patterns is the first step toward avoiding unnecessary alarms.
A true cost anomaly, in contrast, represents an unexpected deviation that cannot be explained by your usual operational behaviors. It may point to configuration errors, forgotten test environments, runaway processes, or even security incidents that require immediate attention.
Normal Spending Fluctuations
Cloud spend naturally varies due to predictable factors such as business growth, seasonal usage spikes, and one‑off events:
- Seasonal Patterns. Retailers, for example, often see higher traffic – and thus compute and storage costs – during holidays. While financial services may experience month‑end batch processing spikes
- Promotions & Campaigns. Marketing campaigns or product launches can drive temporary increases in traffic, leading to higher-than-usual resource consumption
- Auto‑Scaling Behaviors. Correctly configured auto‑scaling will spin up additional instances under load, causing cost increases that are expected and proportionate to demand
- Contractual Discounts & Pricing Changes. Scheduled use of Reserved Instances or Savings Plans shifts costs in known ways, and cloud provider pricing updates may slightly alter billing even under constant usage.
True Anomalies
Cost anomalies are deviations that cannot be explained by these expected patterns – typically indicating misconfigurations, runaway workloads, or service glitches:
- Configuration Errors. Unintended provisioning of oversized instances or infinite loops in batch jobs can drive sudden cost surges
- Undeployed Code or Testing Sprawl. Forgotten test environments or CI/CD pipelines running unchecked may consume resources without delivering business value
- External Incidents. Security breaches or third‑party service failures can trigger unplanned data transfers or instance replacements, spiking costs.
How to Differentiate Anomalies from Fluctuations
1. Historical Baseline & Seasonality Modeling
- Time‑Series Decomposition. Use tools like Datadog’s anomaly detection to separate data into trend, seasonal, and residual components – so only the residuals (unexpected changes) trigger alerts
- Rolling Baselines. Establish dynamic baselines that adapt to weekly / seasonal cycles, preventing normal cyclical peaks from appearing anomalous.
2. Dynamic Thresholds & ML‑Driven Detection
- Automated Threshold Calculation. Use AWS Cost Anomaly Detection uses Machine Learning to compute thresholds based on historical spend, distinguishing true anomalies from regular fluctuations
- Algorithm Selection. Use Azure’s AI Anomaly Detector to automatically pick the best model – trend, seasonal, or spike detection – for each cost / time series, reducing manual tuning.
3. Context‑Aware Segmentation
- Tag‑Based Monitors. Segment monitors by tag (project, environment, cost center) so that each cost stream is evaluated against its own historical pattern – avoiding cross‑project noise
- Service‑Level Models. Create separate deviation monitors for high‑variance services (e.g., EC2 vs. S3) to prevent normal traffic changes in one service from tripping alerts for another.
4. Feedback Loops & Alert Refinement
- False‑Positive Labeling. Mark friendly fluctuations (e.g., planned scale‑up) as expected in your tool, allowing its ML model to learn and ignore similar future patterns
- Adjustable Sensitivity. Tune alert sensitivity or require multi‑factor confirmation (e.g., budget overrun and usage spike) to ensure that only material anomalies are surfaced.
Best Practices for Cost Monitoring, Managing, and Preventing Anomalies
A proactive approach to monitoring cloud spending can help you identify anomalies early, optimize your cloud resource allocation, and ultimately prevent budget overruns. By implementing a structured strategy that combines advanced tools, anomaly detection systems, and effective cost control techniques, it’s easier to maintain financial discipline and enhance operational efficiency. Here are some best practices to consider:
Cost Allocation and Tagging
- Tag all resources consistently (by project, department, or environment) to gain granular visibility into spending
- Use these tags to track and report costs, making it easier to identify areas with unexpected expense increases.
Budget Forecasting and Threshold Setting
- Leverage forecasting tools (e.g., AWS Cost Explorer, Azure Cost Management) to establish baseline AWS budgets based on historical usage data
- Set custom thresholds and automated alerts so that deviations from expected costs can be flagged immediately.
Continuous Monitoring and Real-Time Analytics
- Implement monitoring solutions to continuously track key performance and cost metrics
- Use dashboards and reporting tools that provide real-time insights into your cloud spend, enabling timely interventions.
Automated Optimization
- Utilize automation tools to scale resources dynamically, preventing over-provisioning and reducing wasted spend
- Incorporate policies that shut down idle resources or adjust configurations based on real-time cloud usage patterns.
Regular Audits and Reviews
- Conduct periodic audits to validate your spending against forecasted budgets and ensure compliance with financial policies
- Use the audit findings to refine cost management strategies and drive continuous improvement.
Integration of Governance Frameworks
- Develop governance policies that integrate financial and technical controls to enforce cost discipline
- Ensure that spend management is a shared responsibility across both IT and finance teams.
By combining these practices, you can construct an efficient cloud cost management framework that not only proactively detects anomalies – but also supports agile adjustments that align with evolving business needs. This structured approach minimizes the risk of unexpected expenses and maximizes the ROI of your cloud investments.

Tools and Platforms You Can Use to Detect Anomalies
Below is an overview of leading cloud-native and third‑party platforms that empower you to detect anomalies proactively. Each tool leverages Machine Learning or statistical modeling to differentiate true spend irregularities from normal fluctuations, delivers real‑time alerts, and often provides root‑cause insights to accelerate resolution.
AWS Cost Anomaly Detection
AWS Cost Anomaly Detection applies unsupervised ML to your historical billing data, creating service‑specific monitors (e.g., EC2, S3, Lambda) that adapt to weekly and monthly patterns to minimize false positives. You can configure contextual alerts by AWS service, cost allocation tag, AWS account, or category, with notifications delivered via Amazon SNS or email within 24 hours of detection.
Azure Cost Management & Anomaly Detection
Azure’s Cost Management includes built-in anomaly detection in Cost Analysis smart views, using a WaveNet‑based deep learning model trained on the past 60 days of data to forecast expected daily spending and flag deviations. You can view deviation insights alongside regular cost reports and drill into resource‑group‑level details to pinpoint the root cause.
Google Cloud Cost Anomaly Detection
Google Cloud’s native anomaly detection continuously monitors hourly spend across projects, comparing actual usage against AI‑driven forecasts that account for seasonal and inter‑day trends to detect spikes within 24 hours of occurrence. The Anomalies dashboard surfaces each event with detailed root‑cause breakdowns by project, service, region, and SKU, and integrates with Pub/Sub for real‑time alert routing.
Third‑Party Cloud Platforms
| Apptio Cloudability | Cloud‑agnostic anomaly detection across AWS, Azure, and GCP. It can analyze multiple daily billing file updates and apply standard deviation analytics to flag spend outliers. |
| VMware CloudHealth (Aria Cost) | Serves multi‑cloud portfolios by automatically identifying unusual spend patterns over the past 90 days and grouping anomalies into active, inactive, or archived states. |
| CloudZero | Connects directly to cloud billing APIs, builds custom cost models that map anomalies to business dimensions (e.g., cost per customer or feature) and delivers real‑time alerts. |
| nOps | Provides a SaaS‑based cost optimization journey that includes anomaly detection powered by ML‑driven insights into AWS spend patterns, highlighting overruns & cost-control actions. |
| Kubecost | Tailored for Kubernetes, this platform analyzes resource‑usage metrics (CPU, memory, storage) against billing data to surface unexpected spend within namespaces or clusters. |
By combining 3 cloud‑native tools and specialized third‑party platforms, you can implement a multilayered approach to cost deviation detection – catching issues early, minimizing false alarms, and ensuring your cloud spend stays aligned with business goals.
Using Machine Learning and AI for Detecting and Managing Cloud Cost Anomalies
AI‑driven anomaly detection platforms use unsupervised learning to model your historical cost patterns and automatically flag deviations. Mobilunity recommends integrating these AI‑powered solutions into your FinOps practice to stay ahead of unexpected cloud expenditures.
Core AI / ML Capabilities in Cost Anomaly Detection
| Dynamic Baselines & Thresholds | Instead of manual static limits, cloud services like AWS Cost Anomaly Detection learn weekly and monthly usage patterns to set context‑aware thresholds, reducing the need for constant tuning. |
| Real‑Time & Hourly Monitoring | Google Cloud’s tool analyzes spend every hour, spotting spikes within 24 hours of occurrence. |
| Multivariate Analysis | Azure’s Anomaly Detector selects the best algorithm for each time series – whether univariate or multivariate – ensuring high precision across diverse data streams. |
| Automated Root Cause Insights | After detecting an anomaly, AI dashboards break down spend by project, service, or SKU, accelerating investigation and resolution. |
Tips for Integration and Workflow Automation
Alert Channels. Publish notifications, for example, to Slack, PagerDuty, or email for immediate, role‑based escalation
CI/CD Hooks. Embed deviation checks in deployment pipelines to prevent runaway costs from test jobs or feature releases
API‑Driven Responses. Many tools provide REST or SDK interfaces to trigger automated resolution – such as pausing costly resources or triggering budget overrides.
Key Performance Indicators to Keep an Eye on
Time to Detection (TTD)
The interval between the actual onset of an anomalous spend event and its discovery or acknowledgment. A shorter TTD reduces the window in which runaway costs can accumulate, directly limiting the risks of budget overrun.
Insight: Top-performing organizations aim for sub‑24‑hour detection using automated ML‑driven tools.
Time to Resolution (TTR)
The total duration from anomaly detection to full resolution of the underlying issue. Faster resolution not only limits ongoing cost exposure but also frees up engineering resources for strategic work.
Insight: Automate resolution steps where possible (e.g., auto‑scaling adjustments, resource shutdowns) to cut TTR.
Cost Impact
The incremental spend attributable to the anomaly is calculated as actual cost minus the expected baseline. Quantifying financial impact helps prioritize anomalies by potential savings and ROI of mitigation efforts.
Insight: For example, a $200 anomaly detected weekly can translate into $1,000–2,000 of avoided spend with proper monitoring cadence.
Anomaly Frequency
The count of distinct anomalous events within a given period (e.g., daily, weekly, monthly). Rising frequency may indicate systemic issues – misconfigurations or inefficient scaling policies – that warrant architectural changes.
Insight: Mature FinOps teams aim to maintain a consistent deviation rate, reflecting a stable, well‑tuned environment.
False Positive Rate
The ratio of alerts flagged as anomalies that, upon investigation, turn out to be expected fluctuations. High false positives lead to alert fatigue, causing real issues to be overlooked. Fine‑tune ML thresholds or use segmentation.
Insight: Utilize feedback loops in your anomaly detection tool to label expected deviations and improve model precision.
Cost Avoidance
The cost saved by detecting and resolving anomalies before they fully impact the budget. Calculated as “Cost Impact X Time Range Coefficient”. Demonstrates the direct financial benefit of your anomaly detection investment and helps justify FinOps tooling.
Insight: Review Cost Avoidance playbooks quarterly to refine monitoring frequency and improve financial controls.
Implementing KPIs
Measure and optimize these KPIs to turn anomaly detection into a proactive, data‑driven discipline – maximizing savings while safeguarding your project budgets.
- Dashboard Integration. Consolidate these KPIs in an interactive FinOps dashboard (e.g., Grafana, Cloud Health) for real‑time cost visibility.
- Automated Reporting. Schedule weekly KPI reports to highlight trends and focus discussions on high‑impact areas.
- Executive Review. Share cost‑avoidance and detection performance metrics with leadership to align on budget controls.
- Continuous Improvement. Use KPI insights to refine anomaly detection configurations, resource tagging, and auto‑scaling policies.
Steps to Resolve Cloud Cost Deviations Once Detected
Root Cause Analysis
Drill Down with Automated RCA Features
Use platform‑native root cause analysis (RCA) to uncover contributing factors by service, account, or tag. AWS, for example, now surfaces up to ten potential root causes per event, enabling rapid identification of cost drivers. Google Cloud’s Cost Anomaly Detection similarly breaks down potential anomalies by project, service, region, and SKU, allowing precise analysis.
Use FinOps Frameworks
Apply the FinOps Anomaly Management framework to standardize your RCA process: define detection tools, document alert mechanisms, and assign clear ownership for resolution tasks. This structured methodology ensures consistency and accountability when investigating anomalies.
Validate with Third‑Party Analytics
Complement cloud‑native insights with third‑party platforms and tools like Anodot, Apptio Cloudability, CloudZero, nOps, Kubecost, and others. Doing so, you’ll have in‑depth behavior charts and custom filters to confirm and enrich your understanding of anomaly origins.
Remediation Measures
Immediate Containment Actions
Once the cause is identified, take quick steps to contain cost impact – such as scaling down or shutting off over‑provisioned instances, suspending runaway container jobs, or disabling misconfigured services. Automate these containment steps via CI/CD pipelines or API‑driven scripts to minimize manual intervention and speed up response times.
Resource Optimization
Perform rightsizing exercises on affected resources – adjust instance sizes, tune auto‑scaling policies, or migrate to more cost‑efficient tiers (e.g., spot instances, reserved capacity). Adopt infrastructure‑as‑code tools (Terraform, Pulumi) to enforce optimized configurations across environments.
Policy Enforcement
Implement guardrails using cloud governance tools – such as AWS Service Catalog, Azure Policy, or Google Cloud Organization Policy – to prevent misconfigurations that led to the anomaly. Define and apply tagging policies to improve accountability and ensure anomalies are promptly traceable.
Prevention and Continuous Improvement
Refine Detection Models
Incorporate feedback loops to label planned events (e.g., promotions, backups) as expected, reducing false positives and improving model precision over time.
Automate Remediation Workflows
Develop serverless functions or runbooks that auto‑handle common anomalies – such as shutting down idle environments – so resolution occurs in minutes rather than hours.
Continuous Baseline Refresh
Regularly update spending baselines and sensitivity thresholds to reflect growth, seasonality, and evolving cloud spending patterns, ensuring anomaly detection remains relevant.
Integrate FinOps Best Practices
Manage anomalies into your broader FinOps practice – combining budget forecasting, cost allocation, and performance KPIs – to maintain disciplined cloud spend and drive long‑term efficiency.
Conclusion
In today’s dynamic cloud environments, avoiding budget surprises starts long before an anomaly ever appears on your billing dashboard. Mobilunity recommends combining proactive financial planning, automated resource controls, and strong governance.
Consider the following proactive steps:
- Establish Clear Budgets and Forecasts. Begin with a well‑defined budget for each team, project, or environment. Use historical usage data and business roadmaps to create realistic forecasts.
- Automate Scaling and Resource Optimization. Remember, unmanaged auto‑scaling groups and on‑demand resource provisioning often drive significant costs.
- Enforce Strong Cloud Governance. Use policy engines (AWS Service Catalog, Azure Policy, Google Cloud Organization Policy) to enforce tagging standards.
- Implement Continuous Monitoring and Alerts. Deploy real‑time dashboards that display current spend against budgets. Configure alerts for both absolute spend thresholds and unexpected usage spikes.
- Optimize the Resource Lifecycle. Adopt a “clean‑up” policy that automatically terminates idle or obsolete resources on a regular basis.
- Foster Cross‑Functional Accountability. And, finally, cloud cost management is not solely the finance team’s responsibility. Embed FinOps practices into your engineering workflows: include cost reviews in every sprint planning session, train developers on efficient architecture patterns, and celebrate cost‑saving wins.
This comprehensive approach not only prevents anomalies – but also drives long‑term efficiency. It enables your cloud development project to innovate confidently, staying sustainable and safe in the cloud.